Graeme Winter
Byte Swap
One of the more annoying things about programming back in the day was byte swapping, when moving binary data from e.g. SGI / Sun over to Alpha or x86. Today this is rarely a problem (everything is little endian) but right now I have a need to make the byte order consistent…
Why do I care/
small ---------------------->big
76543210765432107654321076543210
big <---
-->small
Within the byte the bits are big endian, but between bytes they are little endian. This means if I am using the bits to update e.g. a display (which I am) I need to shuffle them to make sense in the output. This is annoying.
The use case is also to make this fast to work within the parameters of the task.
Tested:
- viper with manual byte wrangling
- pack and unpack with
struct - assembly
As:
import struct
@micropython.viper
def byteswap(a: uint) -> uint:
return ((uint(0xff000000) & a) >> 24) | \
((uint(0x00ff0000) & a) >> 8) | \
((uint(0x0000ff00) & a) << 8) | \
((uint(0x000000ff) & a) << 24)
@micropython.asm_thumb
def byteswap_asm(r0):
# const for masking
mov(r6, 0xff)
# save input
mov(r7, r0)
# byte 3
mov(r1, r7)
mov(r5, 24)
lsr(r1, r5)
and_(r1, r6)
mov(r0, r1)
# byte 2
mov(r1, r7)
mov(r5, 16)
lsr(r1, r5)
and_(r1, r6)
mov(r5, 8)
lsl(r1, r5)
orr(r0, r1)
# byte 1
mov(r1, r7)
mov(r5, 8)
lsr(r1, r5)
and_(r1, r6)
mov(r5, 16)
lsl(r1, r5)
orr(r0, r1)
# byte 0
mov(r1, r7)
and_(r1, r6)
mov(r5, 24)
lsl(r1, r5)
orr(r0, r1)
@micropython.viper
def byteswap_struct(a: uint) -> uint:
b = struct.pack("<I", a)
return uint(struct.unpack(">I", b)[0])
x = 0x11223344
print(hex(x), hex(byteswap(x)), hex(byteswap_asm(x)), hex(byteswap_struct(x)))
Turns out the viper’d Python with bit shifts and the assembly are fairly comparable - allowing for the fact that there is a non-trivial overhead in any µPython function call. The struct version? Sucks. Also non viper’d bit shifting…
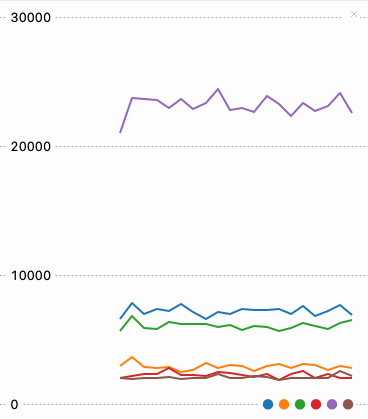
Here we have the time for a nop() type call (red, brown, orange) and the times for assembly (green), viper’d bit shifts (blue) and struct (purple). If I could call rev in the assembly that would probably be super fast but that is not included in the µPython asm_thumb interface 😞.